大语言模型(LLM)上下文长度的爆炸式增长,背后隐藏着哪些关键技术突破?
• 发展轨迹:GPT-3.5-turbo(4k tokens)→ GPT-4(8k tokens)→ Claude 2(100k tokens)→ Llama 3(128k tokens)→ Gemini(1M tokens)
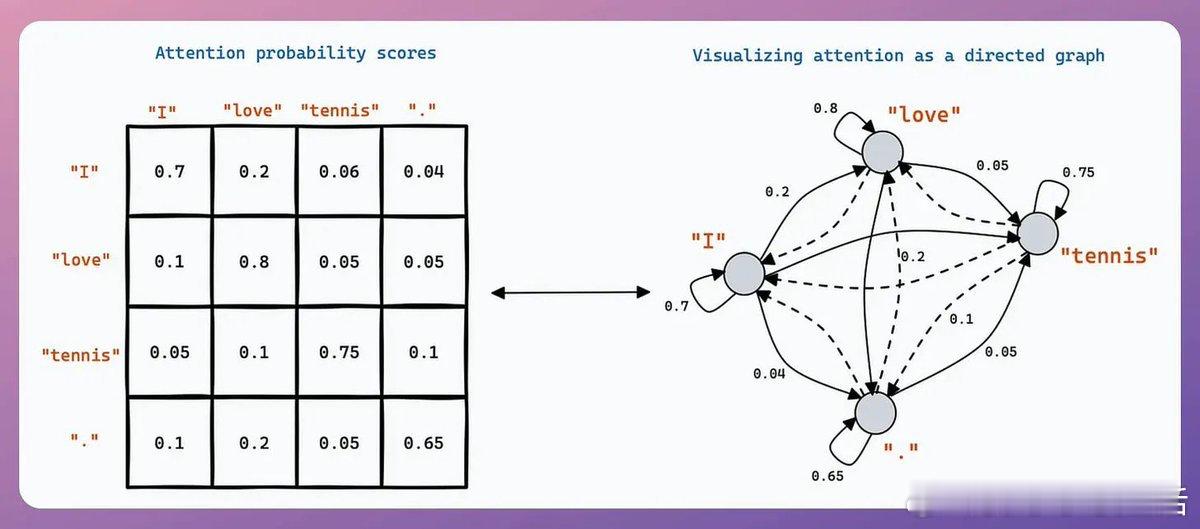
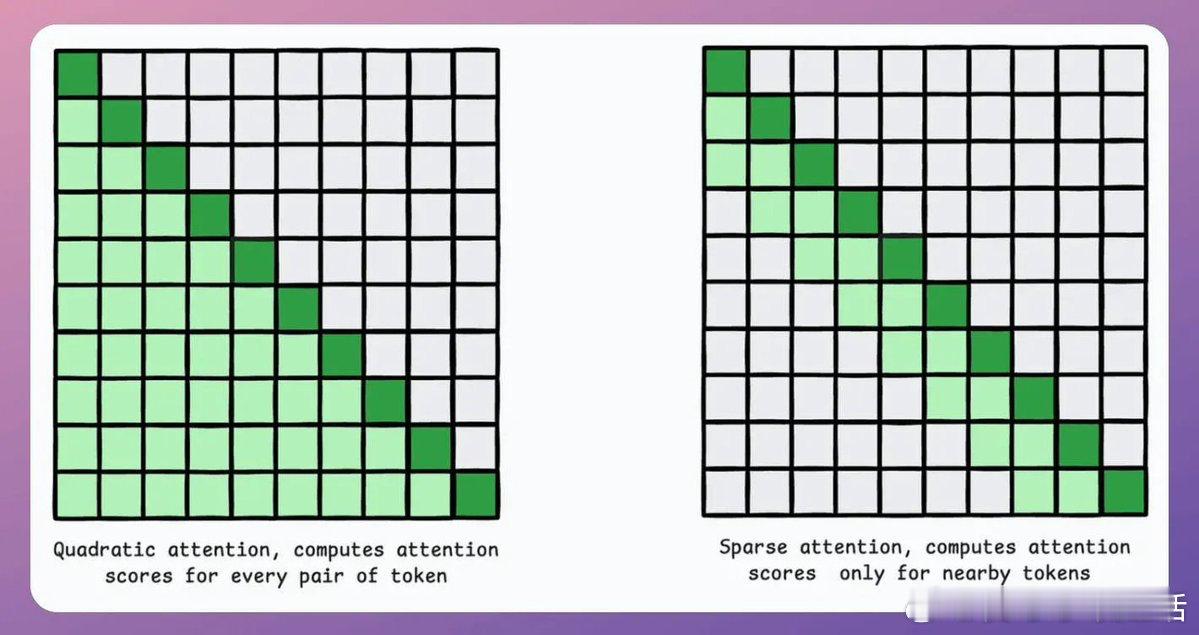
• 计算瓶颈:传统Transformer处理上下文长度“x”的计算量是处理“x” tokens的平方,扩展上下文长度意味着指数级计算增长
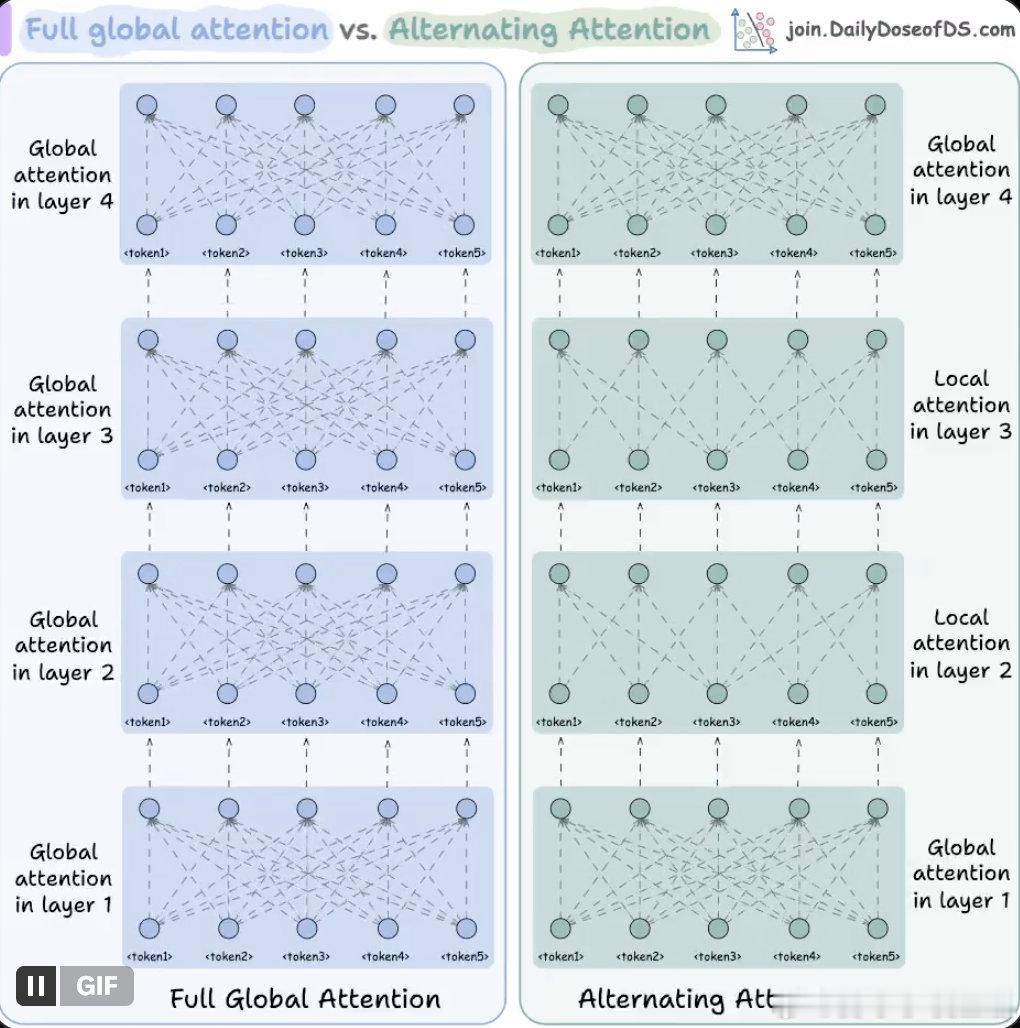
• Sparse Attention稀疏注意力:通过局部关注和动态选择关键token,显著降低计算复杂度,兼顾效率与性能;ModernBERT采用“每三层一次全局注意力,其他层局部128 token”策略,实现16倍序列长度和更低内存占用
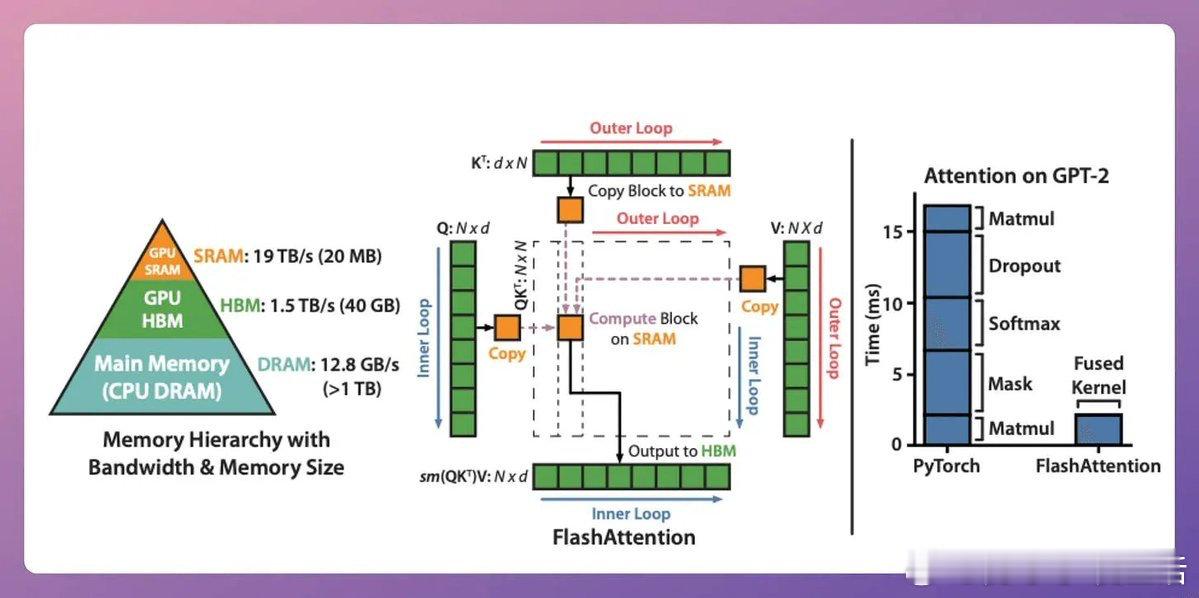
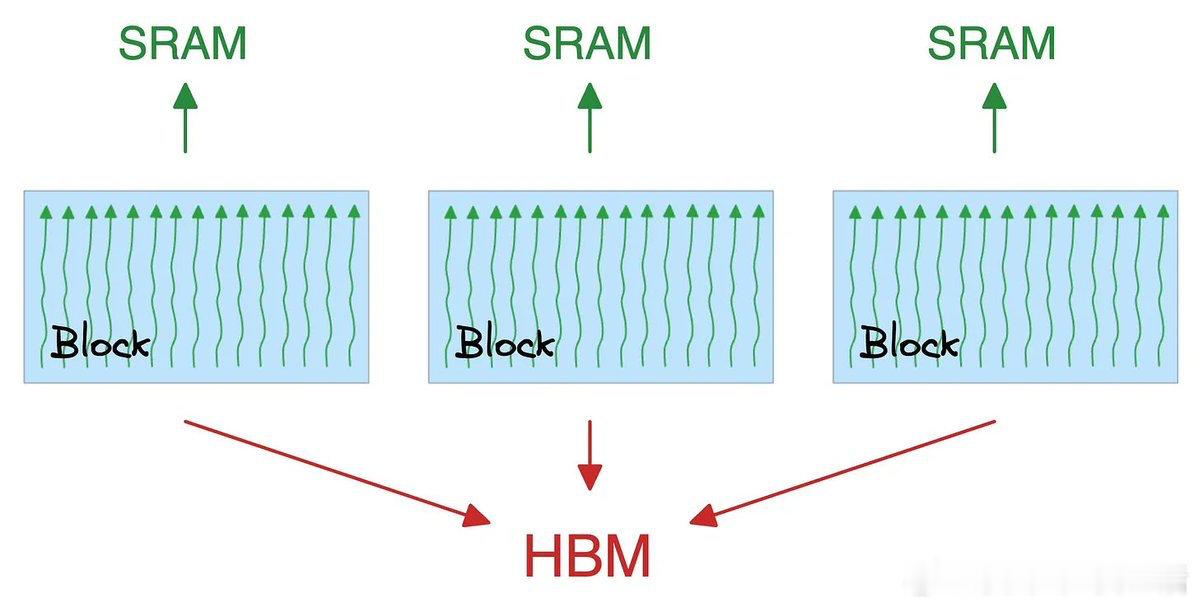
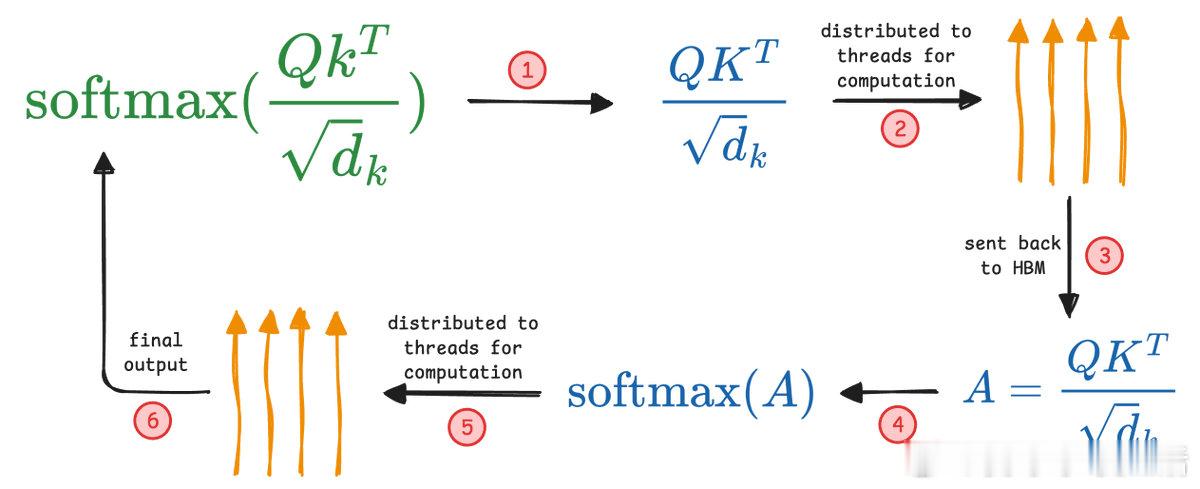
• Flash Attention闪电注意力:硬件级优化,利用SRAM缓存中间计算,减少GPU内存间数据传输,提升速度高达7.6倍,保留全局注意力精度
• 设计洞见:如同阅读一本书,局部理解章节内容加上偶尔回顾全局,远比全程全局关注更高效且合理
• 持续挑战:上下文长度的增长不仅是量的扩张,更是如何保持信息相关性与推理深度的平衡,未来模型需更智能地“选择记忆”,而非单纯拉长记忆窗口
长上下文不是越长越好,而是如何在计算资源和理解深度间找到最佳折中,真正提升模型的思考维度。
详情解读🔗 x.com/_avichawla/status/1959141055301132516
大语言模型 机器学习 自然语言处理 AI技术 Transformer 高效计算