图解RAG和微调区别RAG和微调怎么选
想让大模型更懂业务,其实就两条路:RAG,或者Fine-tuning。
但这俩的区别是:
- RAG(检索增强生成):模型在运行时连网,实时查资料,外部知识随用随取;
- Fine-tuning(微调):把专业知识写进模型权重里,离线训练、一次到位。
两者的使用方式和侧重点也不同:
1. RAG是“外脑”,适合知识更新快、实时性强的场景,比如客服、问答系统、资料整合。
2. Fine-tuning是“内化”,适合高精准、标准化的任务,比如合同审阅、医学报告分析。
RAG不需要改模型权重,调试快、上线快;Fine-tuning则更繁琐,训练周期长,但适应度高。
背后的技术原理也不同——
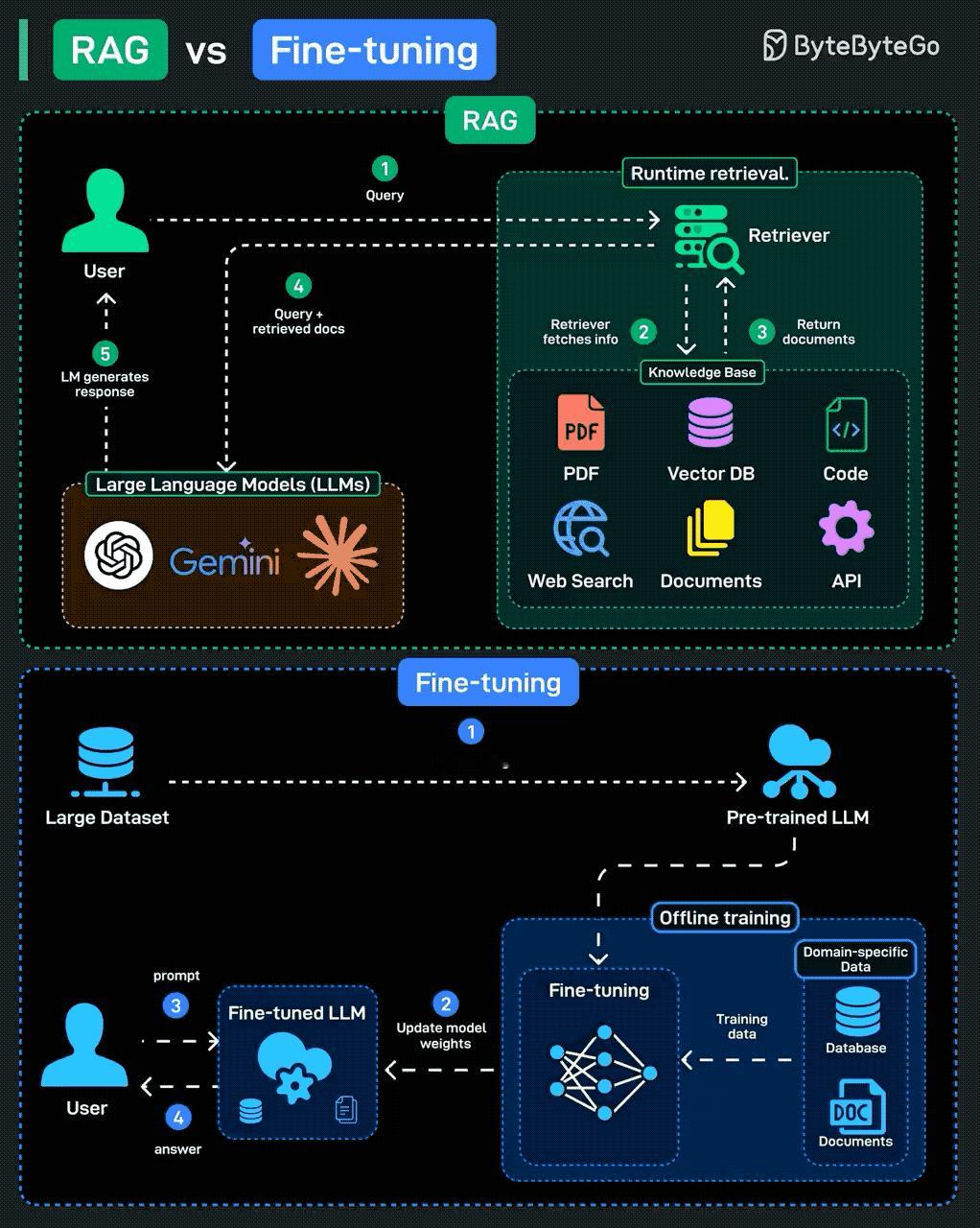
在RAG流程里:
1. 用户发出一个query(问题);
2. 检索模块从外部知识库里抓信息,这些知识库可以是PDF、数据库、代码、API、网页、文档;
3. 把找到的内容返回给大模型;
4. 大模型综合检索结果,再生成回答。
而Fine-tuning这边:
1. 先用大数据集预训练出一个基础模型;
2. 然后喂给它领域内的数据(比如数据库、专业文档),通过离线训练更新模型参数;
3. 最终生成一个专用版模型,后续回答不再依赖外部检索,直接靠“内功”输出。
选哪条路,就看你是更在意“最新信息”,还是“专业深度”。