华尔街日报搞了个实测:四个大模型炒股,DeepSeek-V3 四周赚了8.4%,GPT-4o 反而亏了3.2%。 国内没咋吵,不是没人看见,是真不好说——美股模拟盘碰上A股合规红线,财经博主连“收益”俩字都得绕着走。 再加上那会儿鸿蒙NEXT刚公测,谁还顾得上转发一篇付费墙里的英文报道? 但事情没完。 财联社24号放出新料:幻方、明汯这些顶级量化私募,拿DeepSeek-V3回测A股五年数据,年化超额近19%,回撤还比GPT-4o小一半。 关键在哪儿? 这模型啃得动中文财报、听得懂产业链里的“弦外之音”,政策文件、专家聊天记录一喂就懂。 GPT再强,终究是隔着一层语言和市场的玻璃。 说白了,不是国产模型突然开挂,是它生在中文地界,长在A股土壤里。 老外模型再聪明,看不懂“专精特新”背后的政策红利,也读不懂券商纪要里的潜台词。 这次跑赢,赢在“接地气”,不是运气。 接下来,该有人拿着财联社这把尺子,量一量谁真能打、谁只会吹了。

台积电称将加速美国产能,呼吁大陆保证稀土供应,否则产能将瘫痪!台积电首席执行
【50评论】【13点赞】

![10年后,我们的人均GDP至少需要达到2.4-3万美元的水平上[赞]](http://image.uczzd.cn/14502675602812268274.jpg?id=0)


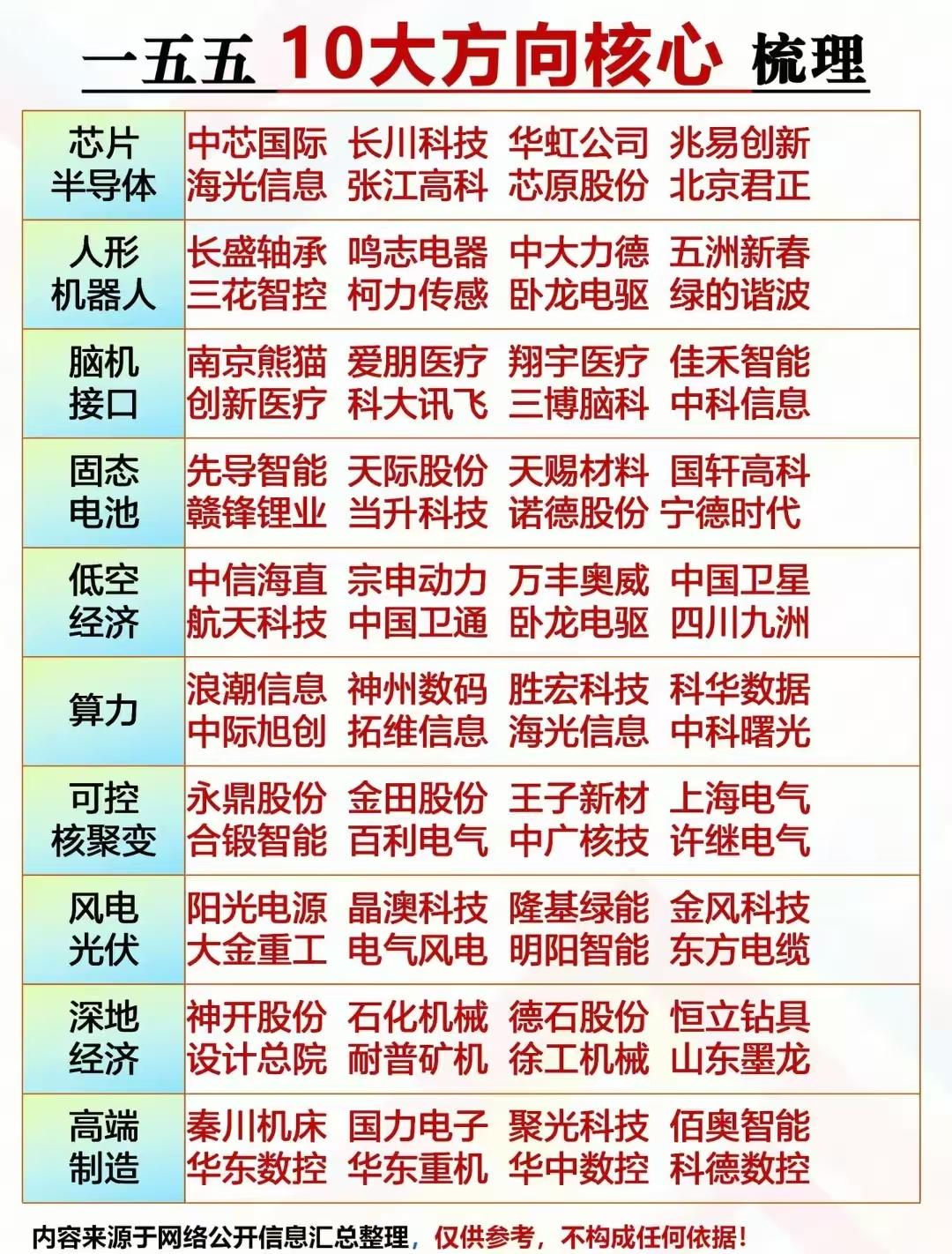



东哥
华尔街日报实测deepseek在英文环境也比GPT强,到国内你就扯上中文环境了。承认国产强就那么难吗?
东哥
据说是国外测试,买的虚拟货币,这跟国内中文财经有什么关你?模型的获取的信息不都是英文吗?