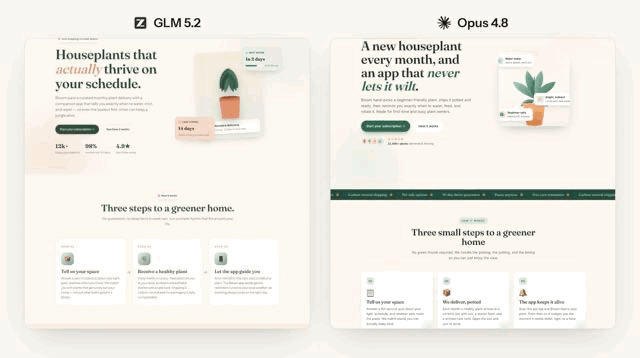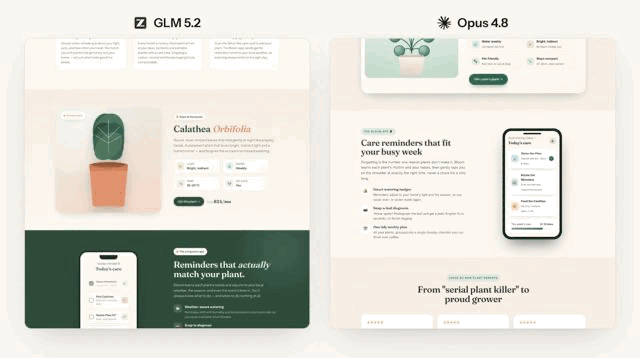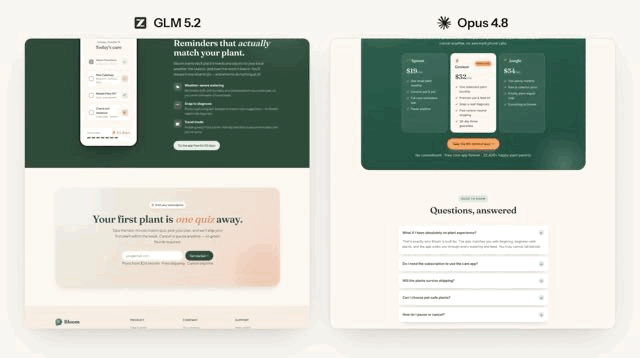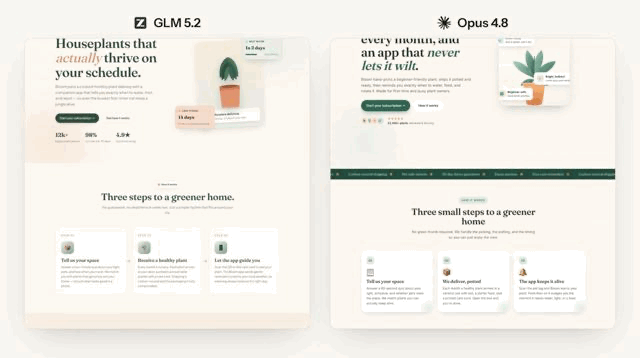
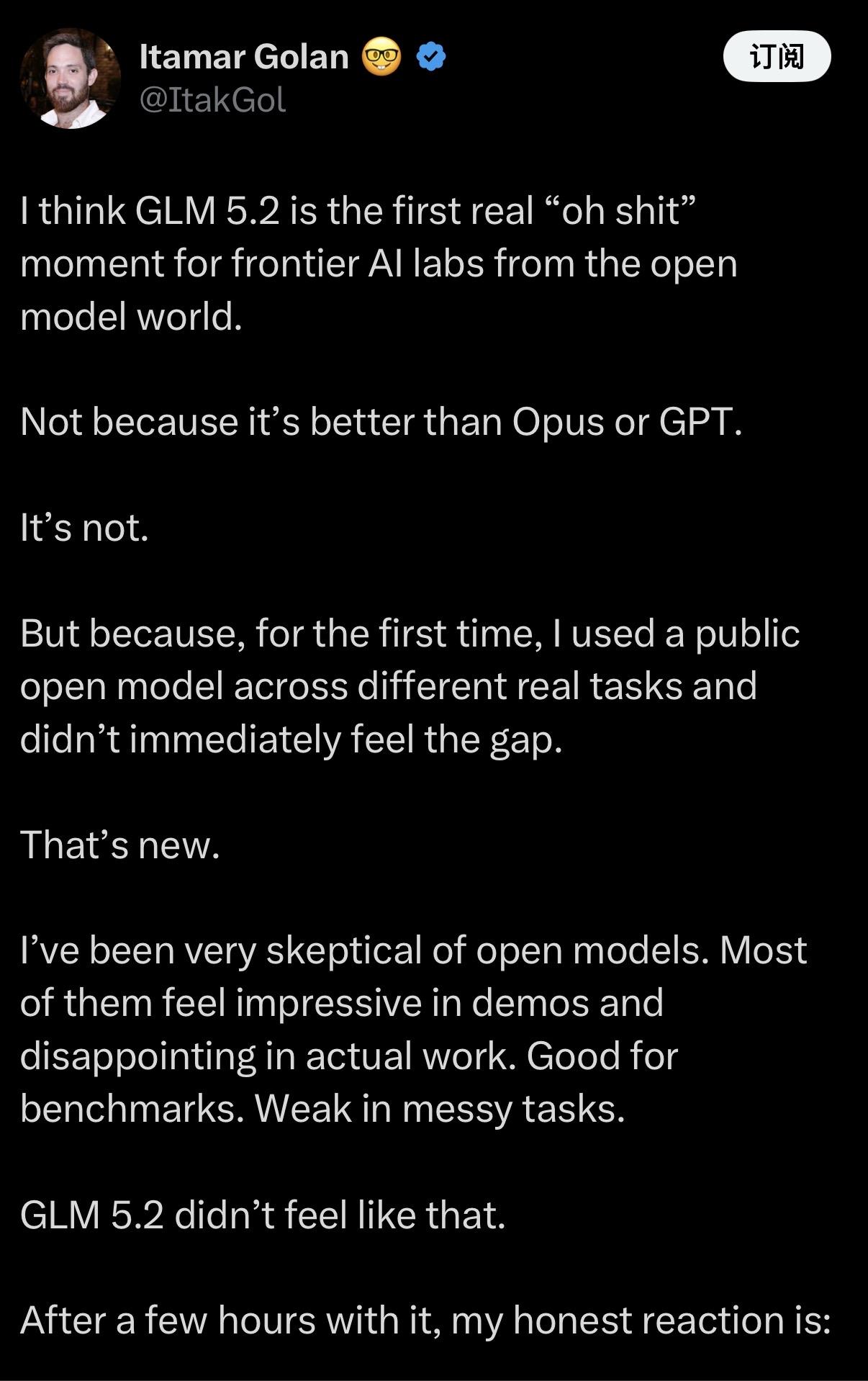
最近,Snowflake的 CEO 公布了他们对国产模型和海外模型的终极测试结果!
专家把国产新秀 GLM-5.2 和海外顶流 Opus-4.7 拉到同一个考场(dbt-bench 基准测试),死磕了103个任务。
结果扒出来的细节,简直就是两个性格截然相反的“AI打工人”。
我们用四个词来拆解这场中美AI的巅峰对决:
1. 战绩:大分打平,小分落后
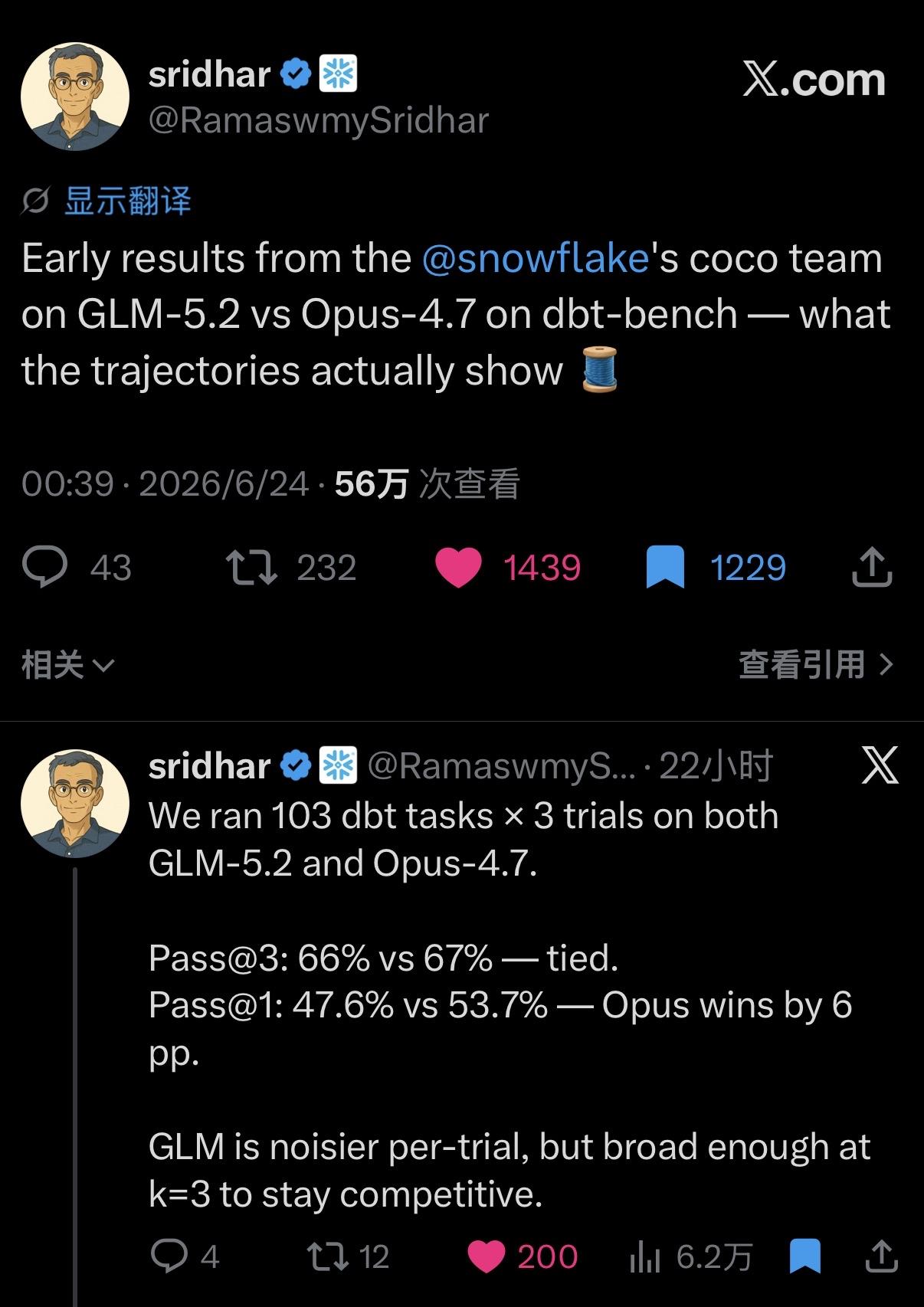
给三次机会,只要对一次就行(Pass@3),GLM-5.2 拿下66%,Opus-4.7 是67%,双方基本持平。
但如果要求一枪爆头、一次做对(Pass@1),Opus 领先了6个百分点。GLM 的发挥还像心电图一样,波动挺大。
2. 消耗:国产模型更“费流量”
虽然综合胜率差不多,但 GLM 的做题成本太高了。
它平均一个任务要跑99轮,Opus 只要80轮。更夸张的是,GLM 耗费了8.6亿个 Token,足足是 Opus 的两倍!
3. 性格:强迫症晚期 vs 云淡风轻
为什么 GLM 这么费流量?因为它太内耗了。
遇到难题,它会疯狂调用411次工具,卡着查了24分钟的空值、行数和一致性,结果这题还是得了零分。这就是在错误的路上穷尽验证。
反观 Opus,49次调用、9分钟,做完交卷。而且 GLM 还容易道心破碎,一看写不出来,直接提早放弃。
4. 绝招:双平台通吃
GLM 也不是白死磕的。它有一个独门绝技:
双平台(DuckDB + Snowflake)联合验证。
在需要两个平台都稳妥的复杂任务里,GLM 靠着这招死磕赢了 Opus。
这其实就是中美AI技术竞争的缩影。
美国顶尖模型在底层逻辑、单次精度和能效比上,依然底蕴深厚,像个高冷学霸。
而中国模型则靠着惊人的迭代速度和工程韧性,把内功消耗拉满,在综合胜率上死死咬住比分。
虽然我用两倍的功力,还偶尔犯强迫症,但拼起命来,我是真能和你打个五五开。
更有意思的是,官方直言,测试框架根本没对 Opus 做任何优化,纯粹是“盲操直接跑”。
外国专家现在对 GLM 兴奋得很,正准备把它调优后推给客户。
AI的下半场,谁能把“内耗”治好,谁就能笑到最后。你觉得国产大模型这种“拼命刷题”的战术,能实现弯道超车吗?欢迎评论区聊聊!


评论列表