Meta新范式让AI自己悟大模型开始反思自己
Meta提出AI训练新范式,不靠奖励也能学——也就是AI自己开悟。
传统训练AI的方法有两种,要么让它学人类专家的操作(模仿学习),要么给它设奖励机制(强化学习)引导它摸索。
但这两种方式都有问题:前者难以扩展,后者成本太高,而且很多场景根本没有“奖励”可言。
现在,Meta联合俄亥俄州立大学提出了一个新方法:Early Experience。它不需要奖励、不靠人类专家,而是让AI自己探索,然后从自己做出的“动作→结果”中学习。
这套方法主要分为两种实现:
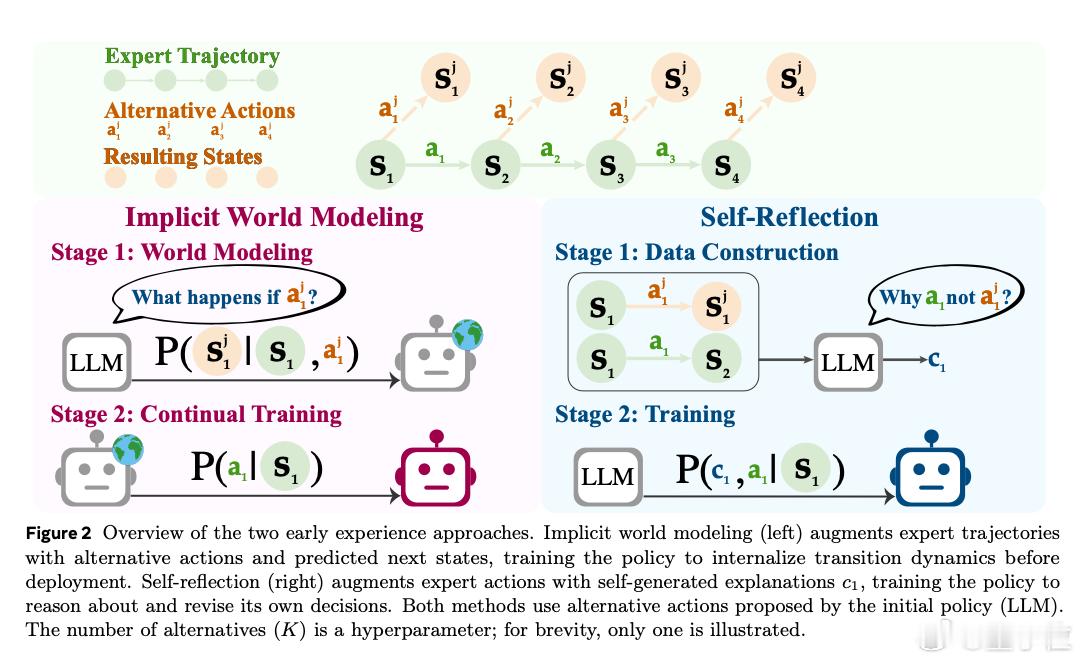
- 一种叫Implicit World Modeling,AI去预测“我如果做了另一个动作,会发生什么”,相当于脑内预演;
- 另一种叫Self-Reflection,AI会反思“为啥我选的这个操作不如专家那个”,并用自然语言总结原因,作为自己的训练数据。
实验结果显示:
- 在WebShop这类复杂网页操作任务中,成功率提升了+18.4%;
- 在TravelPlanner这类规划任务中,提升高达+15%;
- 总共在8个环境里测试,所有任务都优于传统模仿学习。
关键是,它还解决了AI训练中的“冷启动”问题:就算只有1/8的人类数据,也能跑出比完整模仿学习更好的效果。
网友评论道:这是AI从“你教我做什么”进入“我先试试看,然后自己悟”的时代。