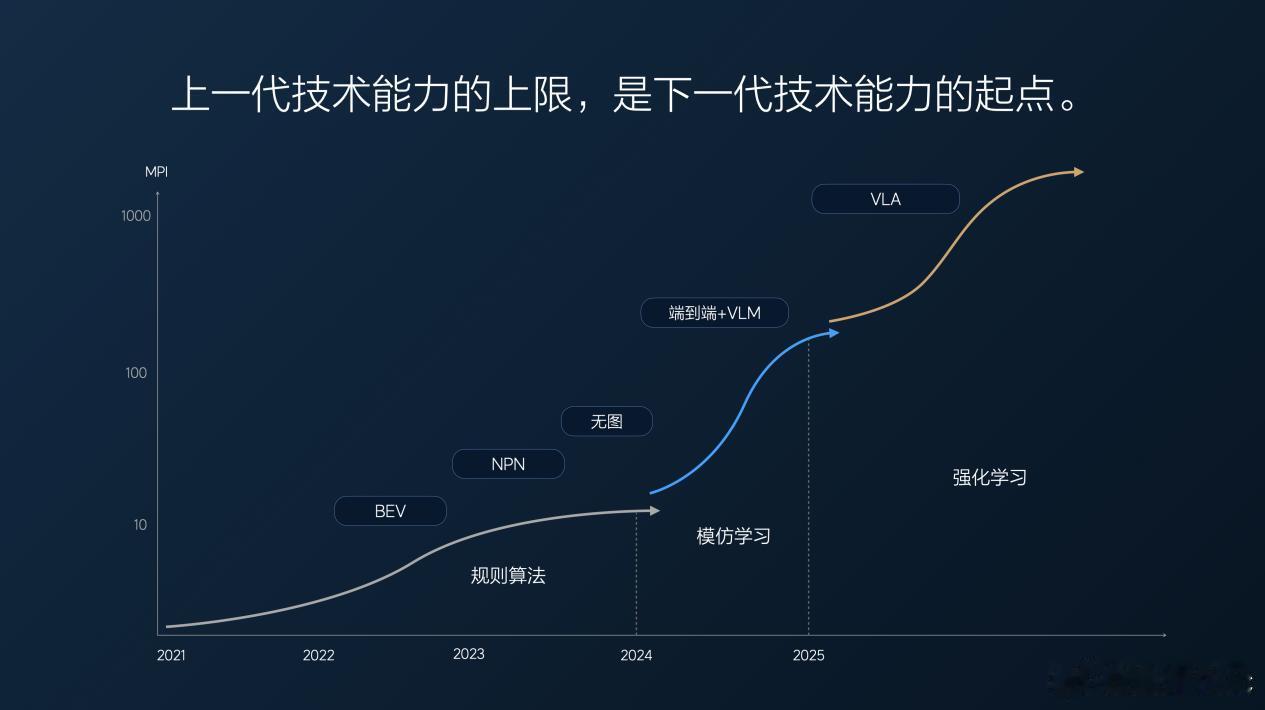
理想的VLA司机大模型9月开始推送,所有的AD Max车型都可以升级(Thor-U平台与Orin-X平台)。之前的端到端的模仿学习本身不具备深度的逻辑思维能力,
会导致三个问题:1、违反常理的行为;2、开车不够聪明,做决策时没有深度思考;3、安全感不足,不能根据场景做出预防性判断。为了解决这些问题,理想引入VLM视觉语言模型,希望将VLM的深度决策能力赋能给端到端模型,但VLM和端到端之间的沟通壁垒,以及VLM较慢的推理速度,都是端到端+VLM现存的问题,因此理想推出VLA司机大模型。
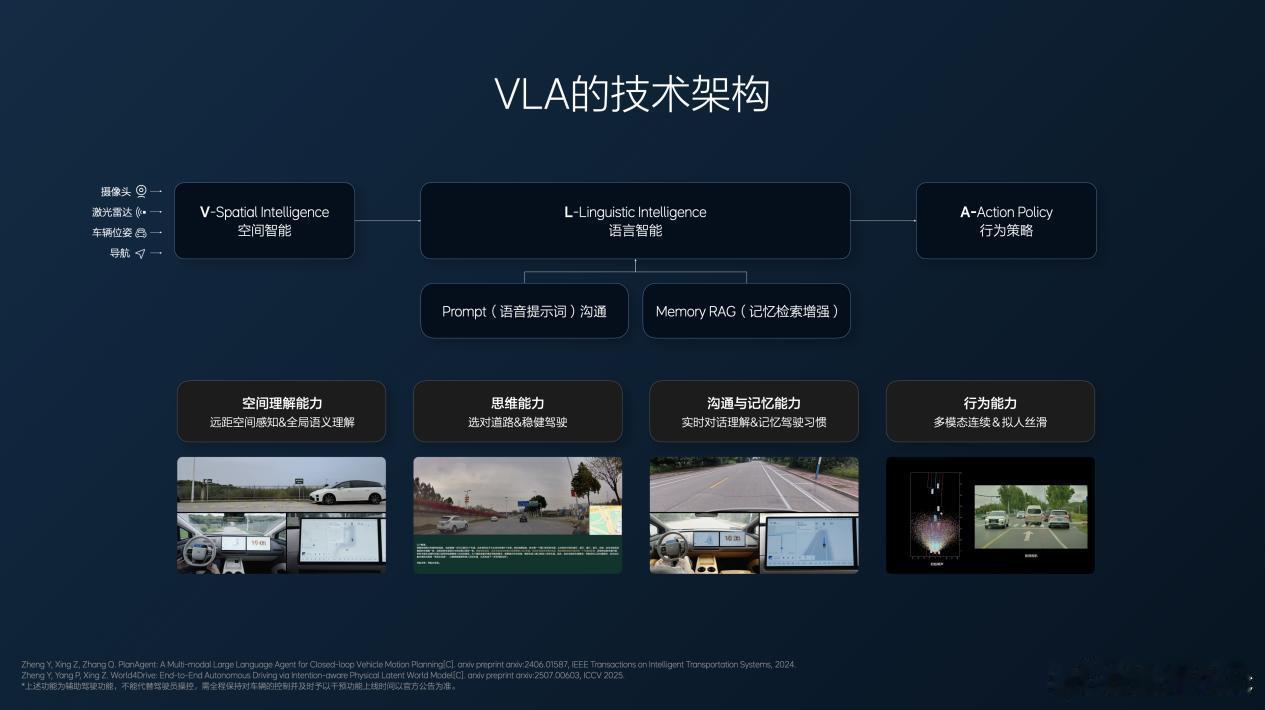
那么什么是VLA?
“V”代表模型对空间的理解能力,例如远距空间感知和全局语义理解能力。各类传感器(主要是视觉传感器)以及导航信息输入模型,让模型具备精细化感知和理解空间的能力。
“L”指的是用语言生成对空间的理解,模型把在空间内感知到的所有内容,用高度压缩的编码表达出来,输出决策。模型不仅可以在内部通过CoT思维链生成决策,人类也可以在外界直接给模型决策。因为有语言智能的存在,因此VLA天生就能听得懂人类语言。此外,VLA经过联合训练后,推理速度达到10赫兹及以上。
“A”根据对场景高度压缩的描述进行推理,并生成最终的行为。与端到端最大的不同是,VLA使用了Diffusion扩散模型规划轨迹。传统的轨迹规划是将轨迹点连成一条折线,再用数学方式人为拟合成光滑曲线;Diffusion扩散模型直接可以生成平滑的行车轨迹,并且Diffusion可以根据决策生成多种行车轨迹,让车辆完成更多驾驶的可能性(驾驶技巧)。
学会了吗[doge]感觉得拍个长视频解释什么是VLA